Abstract
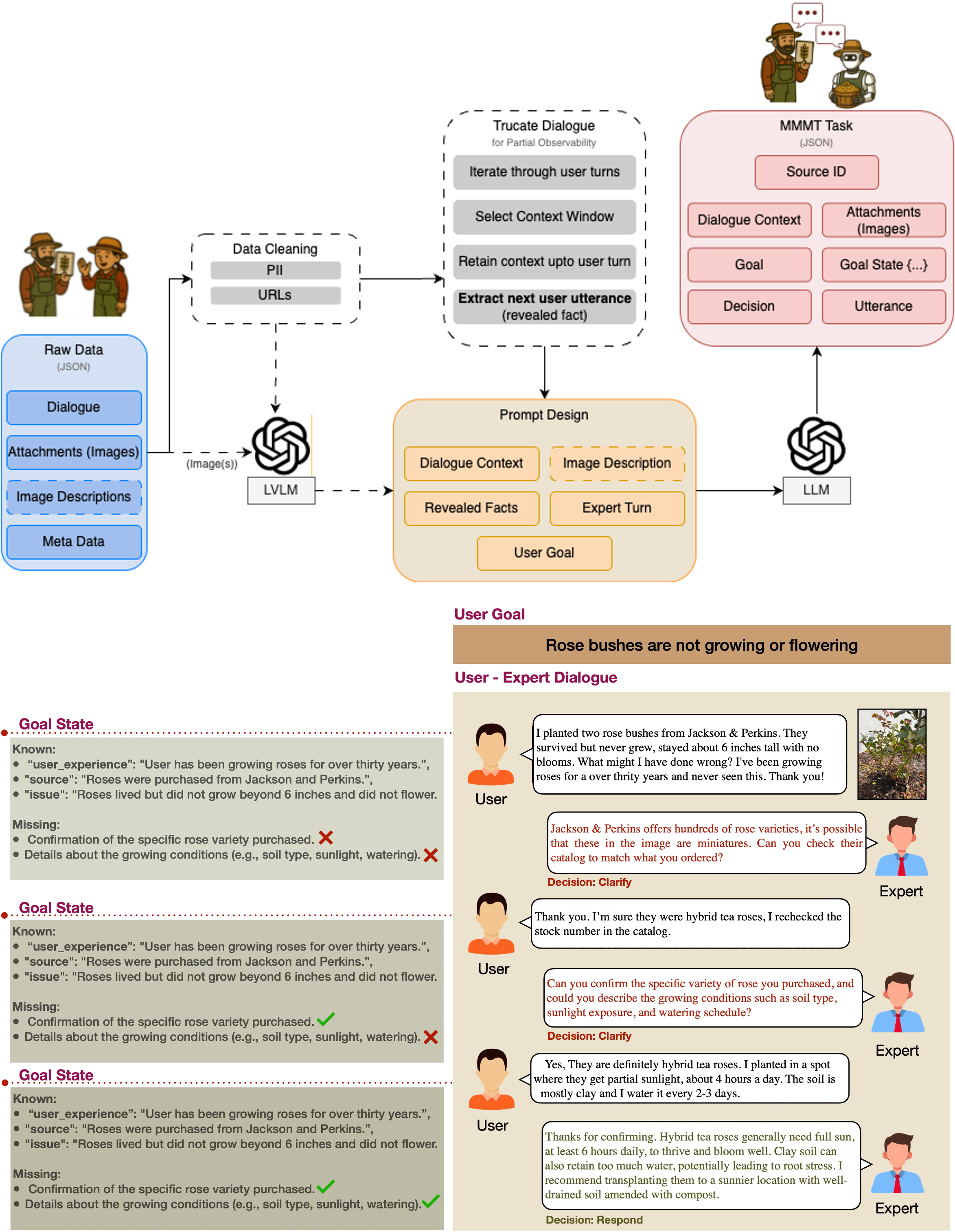
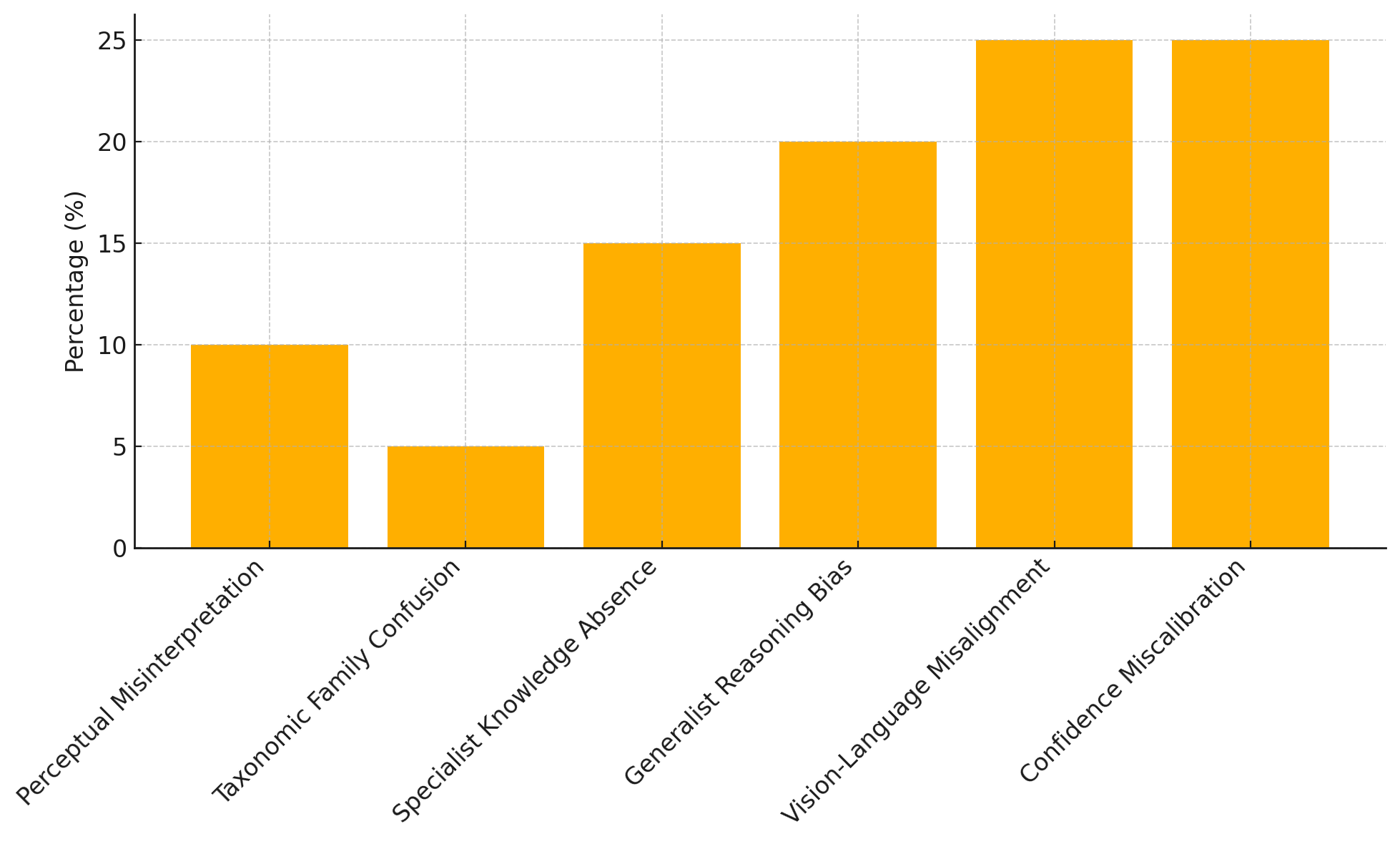
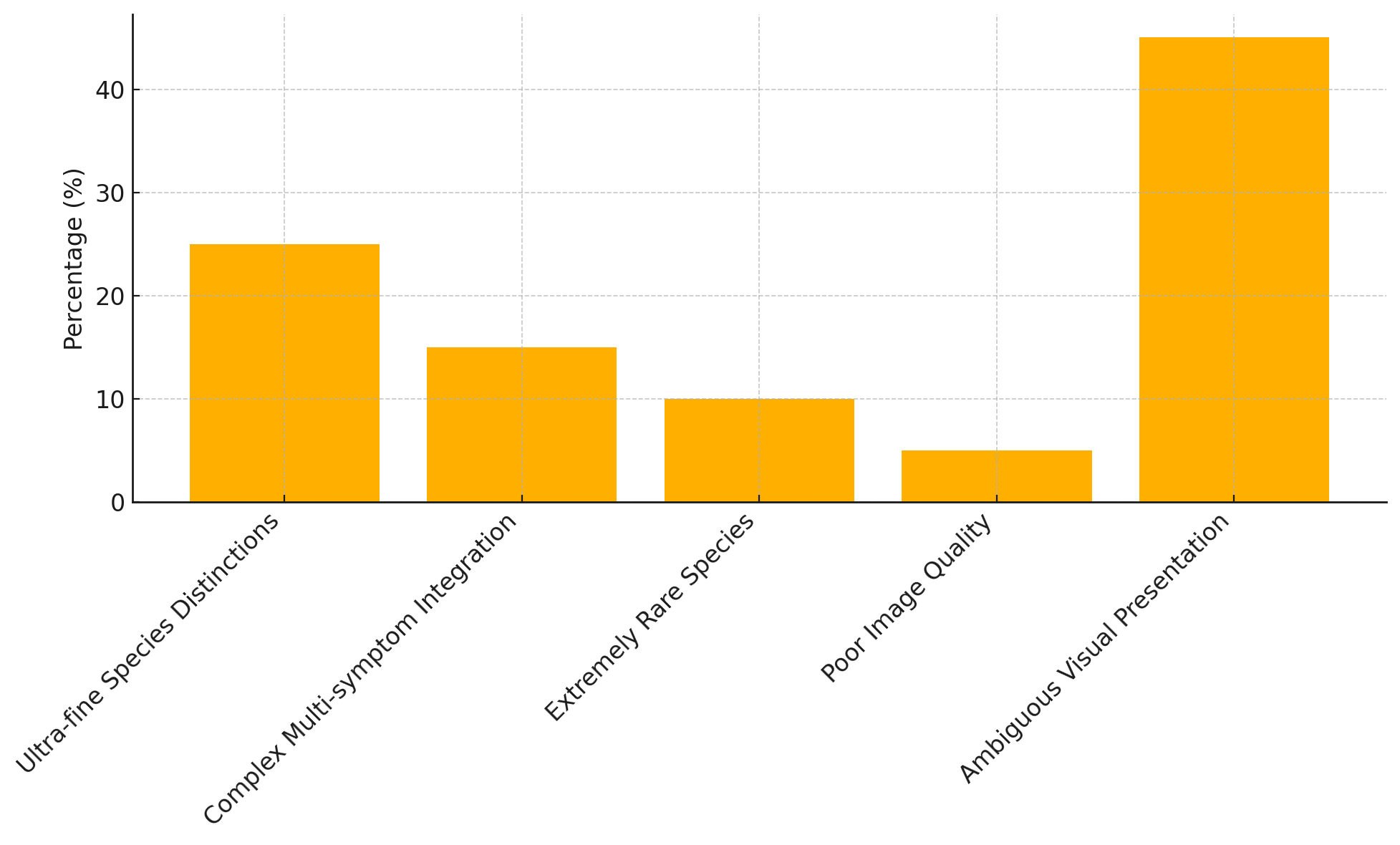
MIRAGE is a new multimodal benchmark designed to evaluate vision-language models in realistic expert consultation settings. MIRAGE incorporates natural user queries, expert responses, and images derived from real interactions between real users and domain experts. It presents challenges such as underspecified information and rare biological entities, which current models struggle with, highlighting a need for improved grounded reasoning, clarification abilities, and long-form response generation. The benchmark includes both single-turn (MIRAGE-MMST) and multi-turn (MIRAGE-MMMT) tasks, assessing not just accuracy, diagnostic parsimony but also the ability to simulate expert conversational decisions, such as whether to clarify or respond.
Drawing on approximately 285 000 real-world agricultural consultations from the AskExtension platform (218 431 single-turn Q&A and 66 962 multi-turn dialogues) and encompassing over 7 000 unique plant, pest, and disease entities, MIRAGE offers both multimodal single-turn and multimodal multi-turn challenges.
MIRAGE provides a rigorous testbed for evaluating vision–language models on critical AI capabilities: grounded reasoning, through complex cause-effect inference tasks; multimodal understanding, by requiring fine-grained recognition from real-world user images; and conversational decision-making, by simulating dynamic, multi-turn expert consultations that challenge models to clarify ambiguities or deliver immediate guidance.